

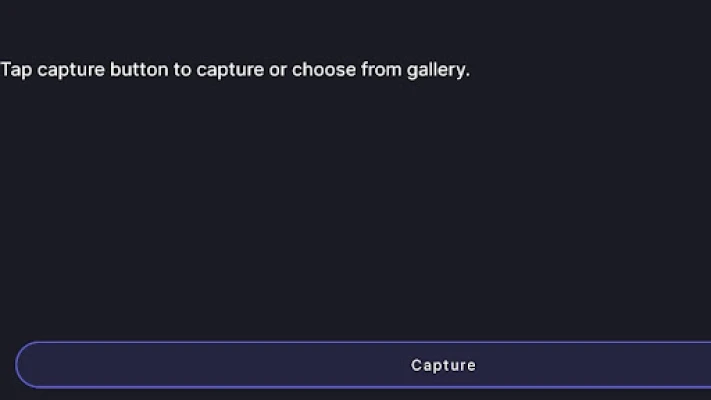

Latest Version
Version
1.9
1.9
Update
October 01, 2025
October 01, 2025
Developer
Flying Cat
Flying Cat
Categories
Productivity
Productivity
Platforms
Android
Android
Downloads
0
0
License
Free
Free
Package Name
com.boss.android.kokoko
com.boss.android.kokoko
Report
Report a Problem
Report a Problem
More About Image to text converter OCR
An image to text converter, commonly referred to as Optical Character Recognition (OCR), is an advanced technology that employs sophisticated algorithms to extract textual information from images or scanned documents. It revolutionizes the way we interact with physical content by enabling the automatic conversion of printed or handwritten characters into editable and searchable text.
The process of converting an image to text involves several intricate steps, each playing a crucial role in achieving accurate results. Initially, the image containing the text is acquired through a digital camera or a scanning device, ensuring sufficient resolution and clarity for optimal OCR performance.
To enhance the image quality and improve OCR accuracy, pre-processing techniques are applied. These techniques encompass various operations, such as noise reduction, contrast adjustment, and image rotation, which aim to optimize the readability of the text within the image.
Once the image is appropriately pre-processed, the OCR system proceeds to the text detection phase. Through a combination of advanced algorithms and pattern recognition methods, the system analyzes the image to identify and locate regions that contain text. By evaluating properties like contrast, texture, and geometric features, the OCR system can accurately distinguish text from other elements in the image.
Next, the OCR system performs character segmentation, which involves dividing the identified text regions into individual characters. This process is particularly challenging when dealing with cursive handwriting or characters that are closely connected. Robust segmentation algorithms are employed to separate characters effectively, ensuring accurate recognition in the subsequent steps.The core of the OCR technology lies in the Optical Character Recognition stage. Using machine learning models, statistical analysis, and pattern matching techniques, the system recognizes and interprets the segmented characters. By comparing them against known character sets, the OCR system assigns textual representations to the recognized characters.
To refine the extracted text further, post-processing techniques are applied. These techniques include error correction algorithms, spell-checking mechanisms, and formatting adjustments to improve the overall accuracy and readability of the extracted text. Post-processing plays a vital role in enhancing the output quality and ensuring a seamless user experience.
Finally, the OCR system generates the output in a format that can be readily utilized. This output can take the form of plain text, a searchable PDF, or even editable document formats like Microsoft Word or HTML. The choice of output format depends on the specific requirements of the user and the intended application of the extracted text.
The applications of OCR technology are vast and diverse. It facilitates the digitization of physical documents, enabling efficient storage, retrieval, and analysis of textual content. OCR is widely used in industries such as banking, insurance, healthcare, and legal, where the need to process vast amounts of paper-based or image-based documents is paramount. Additionally, OCR technology powers various innovative solutions like data extraction from invoices and receipts, text-to-speech conversion for accessibility purposes, and automatic number plate recognition systems.
In summary, an image to text converter or OCR system is a sophisticated technology that utilizes a combination of image processing, pattern recognition, and machine learning techniques to extract text from images or scanned documents. Its ability to transform printed or handwritten characters into editable and searchable text streamlines workflows, enables efficient information retrieval, and opens up new possibilities for data analysis and automation in numerous industries.
To enhance the image quality and improve OCR accuracy, pre-processing techniques are applied. These techniques encompass various operations, such as noise reduction, contrast adjustment, and image rotation, which aim to optimize the readability of the text within the image.
Once the image is appropriately pre-processed, the OCR system proceeds to the text detection phase. Through a combination of advanced algorithms and pattern recognition methods, the system analyzes the image to identify and locate regions that contain text. By evaluating properties like contrast, texture, and geometric features, the OCR system can accurately distinguish text from other elements in the image.
Next, the OCR system performs character segmentation, which involves dividing the identified text regions into individual characters. This process is particularly challenging when dealing with cursive handwriting or characters that are closely connected. Robust segmentation algorithms are employed to separate characters effectively, ensuring accurate recognition in the subsequent steps.The core of the OCR technology lies in the Optical Character Recognition stage. Using machine learning models, statistical analysis, and pattern matching techniques, the system recognizes and interprets the segmented characters. By comparing them against known character sets, the OCR system assigns textual representations to the recognized characters.
To refine the extracted text further, post-processing techniques are applied. These techniques include error correction algorithms, spell-checking mechanisms, and formatting adjustments to improve the overall accuracy and readability of the extracted text. Post-processing plays a vital role in enhancing the output quality and ensuring a seamless user experience.
Finally, the OCR system generates the output in a format that can be readily utilized. This output can take the form of plain text, a searchable PDF, or even editable document formats like Microsoft Word or HTML. The choice of output format depends on the specific requirements of the user and the intended application of the extracted text.
The applications of OCR technology are vast and diverse. It facilitates the digitization of physical documents, enabling efficient storage, retrieval, and analysis of textual content. OCR is widely used in industries such as banking, insurance, healthcare, and legal, where the need to process vast amounts of paper-based or image-based documents is paramount. Additionally, OCR technology powers various innovative solutions like data extraction from invoices and receipts, text-to-speech conversion for accessibility purposes, and automatic number plate recognition systems.
In summary, an image to text converter or OCR system is a sophisticated technology that utilizes a combination of image processing, pattern recognition, and machine learning techniques to extract text from images or scanned documents. Its ability to transform printed or handwritten characters into editable and searchable text streamlines workflows, enables efficient information retrieval, and opens up new possibilities for data analysis and automation in numerous industries.
Rate the App
Add Comment & Review
User Reviews
Based on 0 reviews
No reviews added yet.
Comments will not be approved to be posted if they are SPAM, abusive, off-topic, use profanity, contain a personal attack, or promote hate of any kind.















More »

Popular Apps

phpFoxPHPFOX LLC

Moon Chai StoryOlha Dobel

World War Heroes — WW2 PvP FPSAzur Interactive Games Limited

Govee LiteGovee

Build World AdventureExplore city in cube world

Viking Clan: RagnarokKano Games

Vikings: War of ClansPlarium LLC

Asphalt 9: LegendsGameloft SE

Submarine Car Diving SimulatorSwim with dolphins & penguins

Dawn of Zombies: Survival GameRoyal Ark
More »
Editor's Choice

Grim Soul: Dark Survival RPGBrickworks Games Ltd

Craft of Survival - Gladiators101XP LIMITED

Last Shelter: SurvivalLong Tech Network Limited
Dawn of Zombies: Survival GameRoyal Ark

Merge Survival : WastelandStickyHands Inc.

AoD Vikings: Valhalla GameRoboBot Studio
Viking Clan: RagnarokKano Games
Vikings: War of ClansPlarium LLC
Asphalt 9: LegendsGameloft SE

Modern Tanks: War Tank GamesXDEVS LTD